Talk to us
No meetings are currently scheduled.
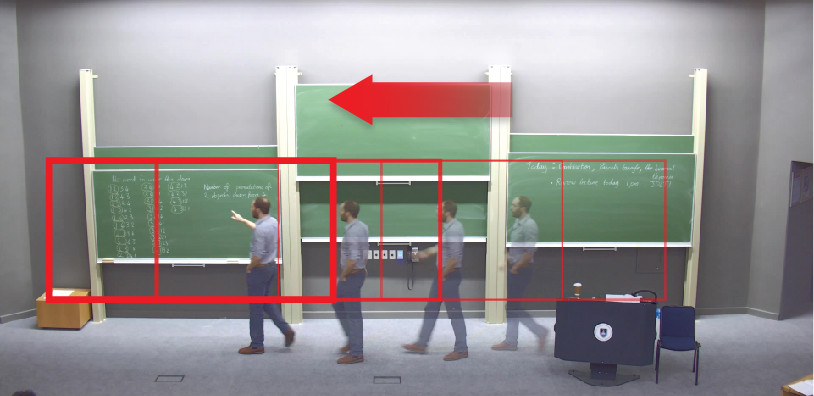
The Centre for Innovation in Learning and Teaching implements an automated lecture recording system at the University of Cape Town and are exploring the potential of using a 4K or higher resolution static camera to capture lectures. However, since the captured videos of a high-resolution static camera are very large, our post-processing solution utilises only fast CPU-based low-compute cost algorithms and heuristics, running on middle-tier hardware, to approximate a presenter’s motion, gestures and board usage in a range of lecture venues. This tracking information is then passed to an external Virtual Cinematographer to reduce the file size by segmenting a smaller crop region that follows the presenter and provides context. Provisional testing shows that under conditions where lighting is good, and there is only one presenter, the results are positive and sufficiently accurate to guide a virtual cinematographer. Failure cases occur in instances where presenters stand very still in dark or poorly lit environments. Text detection is very accurate and only fails when writing comprises isolated letters or symbols and not words, although this is an edge case since most presenters write words. Further analysis is being done with ground truth labelled data and compared with the output of this implementation.
Images